
Integration of SAP and Hadoop Ecosystems: Proliferation of web applications, social media and internet-of-things coupled with large-scale digitalization of business processes has lead to an explosive growth in generation of raw data. Enterprises across the industries are starting to recognize every form of data as a strategic asset and increasingly leveraging it for complex data driven business decisions. Big Data solutions are being used to realize enterprise ‘data lakes’, storing processed or raw data from all available sources and powering a variety of applications/use-cases.
Big Data solutions will also form a critical component of enterprise solutions for predictive analytics and IoT deployments in near future. SAP on-premise and on-demand solutions, especially HANA platform will need closer integration with the Hadoop ecosystem.
What exactly is ‘Big Data’ ?
Data sets can be characterized by their volume, velocity and variety. Big Data refers to the class of data with one or more of these attributes significantly higher than the traditional data sets.
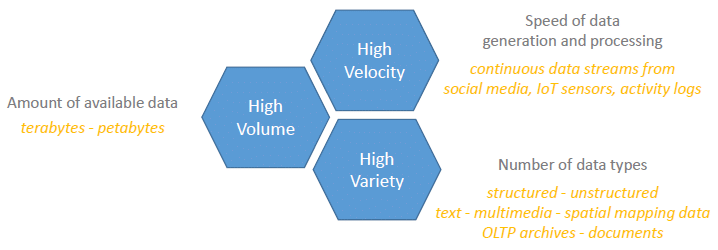
Big data presents unique challenges for all aspects of data processing solutions including acquisition, storage, processing, search, query, update, visualization, transfer and security of the data.
Hadoop Big Data Solution to the Rescue !
Hadoop is an open-source software framework for distributed storage and processing of Big Data using large clusters of machines.
Hadoop’s Modus Operandi –> Divide and Conquer : Break task in small chunks – store / process in parallel over multiple nodes – combine results
Hadoop is not the only available Big Data Solution. Several commercial distributions/variants of Hadoop and other potential alternatives exist which are architecturally very different.
Combining high speed in-memory processing capabilities of SAP HANA with Hadoop’s ability to cost-effectively store and process huge amounts of structured as well as unstructured data has limitless possibilities for business solutions.
Hadoop system can be an extremely versatile addition to any SAP business system landscape while acting as –
- A simple database and/or an low cost archive to extend the storage capacity of SAP systems for retaining large volumes historical or infrequently used data
- A flexible data store to enhance the capabilities of persistence layer of SAP systems and provide efficient storage for semi-structured and unstructured data like xml-json-text-images
- A massive data processing / analytics engine to extend or replace analytical / transformational capabilities of SAP systems including SAP HANA

Getting acquainted : Hadoop Ecosystem
Hadoop at its core is a Java based software library which provides utilities/modules for distributed storage and parallel data processing across a cluster of servers. However, in common parlance the term ‘Hadoop’ almost invariably refers to an entire ecosystem which includes a wide range of apache open-source and/or commercial tools based on the core software library.
Hadoop is currently available either as a set of open-source packages or via several enterprise grade commercial distributions. Hadoop solution are available as SaaS/PaaS cloud offerings from multiple vendors in addition to traditional offerings for on-premise deployments.
Snapshot of prominent distributions/services according to latest market guides from Gartner and Forrester Research :
- Apache Hadoop [open source]
- Cloudera Enterprise | Cloudera CDH [open source]
- Hortonworks Data Platform HDP [open source]
- MapR
- IBM Big Insights ^^
- Amazon Elastic MapReduce (EMR)
- Microsoft Azure HDInsight
- Google Cloud Dataproc
- Oracle Big Data Cloud Services
- SAP Cloud Platform Big Data Service (formerly SAP Altiscale Data Cloud)(^^ Potentially Discontinued Solution)
Hadoop core components serve as foundation for entire ecosystem of data access and processing solutions.
- Hadoop HDFS is a scalable, fault-tolerant, distributed storage system which stores data using native operating system files over a large cluster of nodes. HDFS can support any type of data and provides high degree of fault-tolerance by replicating files across multiple nodes.
- Hadoop YARN and Hadoop Common provide foundational framework and utilities for resource management across the cluster
Hadoop MapReduce is a framework for development and execution of distributed data processing applications. Spark and Tez which are alternate processing frameworks based on data-flow graphs are considered to be the next generation replacement of MapReduce as the underlying execution engine for distributed processing in Hadoop.
Map : Split and distribute job
Reduce : Collect and combine results


Variety of data access / processing engines can run alongside Hadoop MapReduce engine to process HDFS datasets. Hadoop ecosystem is continuously evolving with components frequently having some complementing, overlapping and/or similar appearing capabilities but with vastly different underlying architectures or approach.
Popular components-applications-engines-tools within Hadoop ecosystem (NOT an exhaustive list; several more open source and vendor specific applications are used by enterprises for specific use-cases)
- Pig — Platform for development and execution of high-level language (Pig Latin) scripts for complex ETL and data analysis jobs on Hadoop datasets
- Hive — Read only relational database that runs on top of Hadoop core and enables SQL based querying to Hadoop datasets; Supported by Hive-Metastore
- Impala — Massively Parallel Processing (MPP) analytical database and interactive SQL based query engine for real-time analytics
- HBase — NoSQL (non-relational) db which provides real-time random read/write access to datasets in Hadoop; Supported by HCatalog
- Spark — In-memory data processing engine which can run either over Hadoop or standalone as an alternative / successor to Hadoop itself
- Solr — Search engine / platform enabling powerful full-text search and near real-time indexing
- Storm — Streaming data processing engine for continuous computations & real-time analytics
- Mahout — Library of statistical, analytical and machine learning software that runs on Hadoop and can be used for data mining and analysis
- Giraph — Iterative graph processing engine based on MapReduce framework
- Cassandra — Distributed NoSQL (non-relational) db with extreme high availability capabilities
- Oozie — Scheduler engine to manage jobs and workflows
- Sqoop — Extensible application for bulk transfer of data between Hadoop and structured data stores and relational databases
- Flume — Distributed service enabling ingestion of high-volume streaming data into HDFS
- Kafka — Stream processing and message brokering system
- Ambari — Web based tool for provisioning, managing and monitoring Hadoop clusters and various native data access engines
- Zookeeper – Centralized service maintaining Hadoop configuration information and enabling coordination among distributed Hadoop processes
- Ranger – Centralized framework to define, administer and manage fine-grained access control and security policies consistently across Hadoop components
- Knox – Application gateway which act as reverse proxy, provides perimeter security for Hadoop cluster and enables integration with SSO and IDM solutions
Bridging two worlds – Hadoop and SAP Ecosystems
SAP solutions, especially SAP HANA platform, can be ‘integrated’ with Hadoop ecosystem using a variety of solutions and approaches depending upon the specific requirements of any use case.
SAP solutions which should be considered for the integration include :
- SAP BO Data Services
- SAP BO BI Platform | Lumira
- SAP HANA Smart Data Access
- SAP HANA Enterprise Information Management
- SAP HANA Data Warehousing Foundation – Data Lifecycle Manager
- SAP HANA Spark Controller
- SAP Near-Line Storage
- SAP Vora
- ….
- Apache Sqoop [Not officially supported by SAP for HANA]
SAP HANA can leverage HANA Smart Data Access to federate data from Hadoop (access Hadoop as a data source) without copying the remote data into HANA. SDA enables data federation (read/write) using virtual tables and supports Apache Hadoop/Hive and Apache Spark as remote data sources in addition to many other database systems including SAP IQ, SAP ASE, Teradata, MS SQL, IBM DB2, IBM Netezza and Oracle.
Hadoop can be used as a remote data source for virtual tables in SAP HANA using following adaptors (in-built within HANA):
- Hadoop/Spark ODBC Adaptor — Require installation of Unix ODBC drivers + Apache Hive/Spark ODBC Drivers on HANA server
- SPARK SQL Adaptor — Require installation of SAP HANA Spark Controller on Hadoop Cluster (Recommended Adaptor)
- Hadoop Adaptor (WebHDFS)
- Vora Adaptor
SAP HANA can also leverage HANA Smart Data Integration to replicate required data from Hadoop into HANA. SDI provides pre-built adaptors & adaptor SDK to connect to a variety of data sources including Hadoop. HANA SDI requires installation of Data Provisioning Agent (containing standard adaptors) and native drivers for the remote data source, on a standalone machine. SAP HANA XS engine based DWF-DLM can relocate data from HANA to/between HANA Dynamic Tiering, HANA Extension nodes, SAP IQ and Hadoop via Spark SQL adaptor / Spark Controller.

SAP Vora is an in-memory query engine that runs on top of Apache Spark framework and provides enriched interactive analytics on the data in Hadoop. Data in Vora can be accessed in HANA either directly via Vora Adaptor or via SPARK SQL Adaptor (HANA Spark Controller). Supports Hortonworks, Cloudera and MapR.
SAP BO Data Services (BODS) is a comprehensive data replication/integration (ETL processing) solution. SAP BODS has capabilities (via the packaged drivers-connectors-adaptors) to access data in Hadoop, push data to Hadoop, process datasets in Hadoop and push ETL jobs to Hadoop using Hive/Spark queries, pig scripts, MapReduce jobs and direct interaction with HDFS or native OS files. SAP SLT does not have native capabilities to communicate with Hadoop.
SAP Business Objects (BI Platform, Lumira, Crystal Reports, …) can access and visualize data from Hadoop (HDFS – Hive – Spark – Impala – SAP Vora) with ability to combine it with data from SAP HANA and other non-SAP sources. SAP BO applications use their in-built ODBC/JDBC drivers or generic connectors to connect to Hadoop ecosystem. Apache Zeppelin can used for interactive analytics visualization from SAP Vora.
Apache Sqoop enables bulk transfer of data between unstructured, semi-structured and structured data stores. Sqoop can be used to transfer data between Apache Hadoop and relational databases including SAP HANA (although not officially supported by SAP).
Getting started : Hadoop Deployment Overview
Hadoop is a distributed storage and processing framework which would typically be deployed across a cluster consisting of upto several hundreds/thousands of independent machines, each participating in data storage as well as processing. Each cluster node could either be a bare-metal commodity server or a virtual machine. Some organizations prefer to have a small number of larger-sized clusters; others choose a greater number of smaller clusters based on workload profile and data volumes.
HDFS Data is replicated to multiple nodes for fault-tolerance. Hadoop clusters are typically deployed with a HDFS replication factor of three which means each data block has three replicas – the original plus two copies. Accordingly, storage requirements of a Hadoop cluster is more than four times the anticipated input/managed dataset size. Recommended storage option for Hadoop clusters is to have nodes with local (Direct Attached Storage – DAS) storage. SAN / NAS storage can be used but is not common (inefficient ?) since Hadoop cluster is inherently a ‘share nothing architecture’.
Nodes are distinguished by their type and role. Master nodes provide key central coordination services for the distributed storage and processing system while worker nodes are the actual storage and compute nodes.
Node roles represent set of services running as daemons or processes. Basic Hadoop cluster consists of NameNode (+ Standby), DataNode, ResourceManager (+ Standby) and NodeManager roles. NameNode coordinates data storage on DataNodes while ResourceManager node coordinates data processing on NodeManager nodes within the cluster. Majority of nodes within the cluster are workers which typically will perform both DataNode and NodeManager roles however there can be data-only or compute-only nodes as well.
Deployment of various other components/engines from Hadoop ecosystem brings more services and node types/roles in play which can be added to cluster nodes. Node assignment for various services of any application is specific to that application (refer to installation guides). Many such components also need their own database for operations which is a part of component services. Clusters can have dedicated nodes for application engines with very specific requirements like in-memory processing and streaming.
Master / Management nodes are deployed on enterprise class hardware with HA protection; while the worker can be deployed on commodity servers since the distributed processing paradigm itself and HDFS data replication provide the fault-tolerance. Hadoop has its own built-in failure-recovery algorithms to detect and repair Hadoop cluster components.
Typical specification of Hadoop Cluster nodes depending on whether workload profile is storage intensive or compute intensive. All nodes do not necessarily need to have identical specifications.
- 2 quad-/hex-/octo-core CPUs and 64-512 GB RAM
- 1-1.5 disk per core; 12-24 1-4TB hard disks; JBOD (Just a Bunch Of Disks) configuration for Worker nodes and RAID protection for Master nodes

Hadoop Applications (Data access / processing engines and tools like Hive, Hbase, Spark and Storm, SAP HANA Spark Controller and SAP Vora) can be deployed across the cluster nodes either using the provisioning tools like Ambari / Cloudera Manager or manually.
Deployment requirement could be : All nodes, at-least one node, one or more nodes, multiple nodes, specific type of node

Getting started : Deployment Overview of ‘bridging’ solutions from SAP
SAP Vora consists of a Vora Manager service and a number of core processing services which can be added to various compute nodes of the existing Hadoop deployment
— Install SAP Vora Manager on management node using SAP Vora installer
— Distribute SAP Vora RPMs to all cluster nodes and install using Hadoop Cluster Provisioning tools — Deploy Vora Manager on cluster nodes using Hadoop Cluster Provisioning tools
— Start Vora Manager and Deploy various Vora services across the cluster using Vora Manager
SAP HANA Spark Controller provides SQL interface to the underlying Hive/Vora tables using Spark SQL and needs to be added to at-least one of the master nodes of the existing Hadoop deployment
— Install Apache Spark assembly files (open source libraries); not provided by SAP installer
— Install SAP HANA Spark Controller on master node using Hadoop Cluster Provisioning tools
SAP HANA Smart Data Integration and Smart Data Access are native components of SAP HANA and do not require separate installation. Smart Data Integration do however require activation of Data Provisioning server and installation of Data Provisioning Agents.
— Enable Data Provisioning server on HANA system
— Deploy Data Provisioning Delivery Unit on HANA system
— Install and configure Data Provisioning Agents on remote datasource host or a standalone host
SAP HANA Data Warehousing Foundation – Data Lifecycle Manager is an XS engine based application and requires separate installation on HANA platform.
SAP Cloud Platform Big Data Service (formerly SAP Altiscale Data Cloud) is a fully managed cloud based Big Data platform which provides pre-installed, pre-configured, production ready Apache Hadoop platform.
— Service includes Hive, HCatalog, Tez and Oozie from Apache Hadoop ecosystem in addition to the core Hadoop MapReduce / Spark and HDFS layers
— Supports and provide runtime environment for Java, Pig, R, Ruby and Python languages
— Supports deployment of non-default third-party applications from the Hadoop ecosystem
— Service can be consumed via SSH and webservices
— Essentially a Platform-as-a-Service (PaaS) offering and comprises :
— Infrastructure provisioning
— Hadoop software stack deployment and configuration
— Operational support and availability monitoring
— Enables customers to focus on business priorities and their analytic / data-science aspects
by delegating technical setup and management of the Hadoop platform software stack and
the underlying infrastructure to SAP’s cloud platform support team
Final thoughts
Gartner’s market research and surveys assert that Hadoop adoption is steadily growing and also shifting from traditional the monolithic, on-premise deployments to ad hoc or on-demand cloud instances.
Get ready to accomplish big tasks with big data !!
## Thanks for reading !!New NetWeaver Information at SAP.com
Very Helpfull