
As Hadoop is widely being adopted by enterprises for Big Data storage and processing, many organizations running SAP HANA are looking for effective ways to leverage (as well as integrate) Hadoop in their landscape. In this context, let us look at both platforms and assess various integration options available.
Benefits of Hadoop
Hadoop runs on commodity hardware and is capable of storing huge volumes of data. Data storage is cheaper in Hadoop compared to SAP HANA which would require a lot of memory with which the appliance would become very expensive.
Hadoop is also used as an archival solution. Data that is very old and used for archive is stored in Hadoop so that it can be reused when needed.
Over time, a lot of frameworks have been built over Hadoop which helps in processing data stored in it. Libraries such as Apache Spark, Pig, Flume, and Hive provide the ability to do complex processing of data including large map-reduce or machine learning.
Similarly, actions such as log analysis are easier to store and process in Hadoop as it supports raw HDFS file format which would be an expensive operation in SAP HANA.
Benefits of SAP HANA
SAP HANA is designed to run complex analytic and transactional data processing at high speed. Being an in-memory appliance, it can process large amount of data faster than Hadoop.
SAP HANA comes with a rich set of features modeling features needed to handle data without the need to write any programs. It integrates well with SAP Business Warehouse (BW) and other front end SAP tools. SAP HANA also doubles as an application platform (XS) and an appliance making it easy to execute and deploy applications alongside data without needing any separate application servers. All of these make SAP HANA a complete data platform unlike Hadoop which needs third party tools and libraries to write programs to process data.
SAP HANA comes from a single manufacturer – SAP, while Hadoop comes in various flavors and is backed by Open Source and some enterprise providers such as Cloudera, Horton works and MapR.
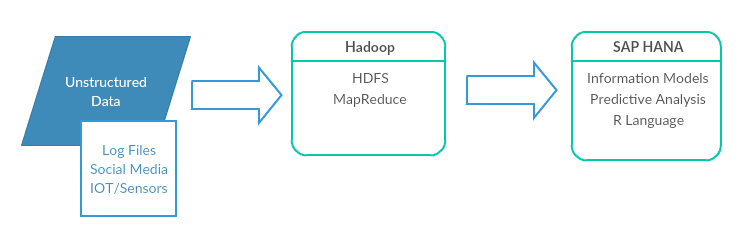
The Hybrid Model: Best of Both Worlds
A hybrid model that leverages both SAP HANA and Hadoop would look like this.
Hadoop would collect and store unstructured data with HDFS and run complex processes with frameworks such as Spark, and SAP HANA would be used to build in-memory analytics and views to easily consume the data for integration (with operational data), reporting & visualization (with other SAP front-end tools).
The design specifics of integrated Hadoop and SAP HANA would depend on the nature of the requirement, and some of the integration scenarios & use cases are listed below:
Scenario 1: Moving Data from Hadoop to SAP HANA
An ETL tool such as SAP BODS can be used to connect month system as shown below.

The unstructured data in Hadoop is processed by means of Spark or other library and is then stored as structured data which is used as source for BODS using Hive adapter. The structured data is then loaded into SAP HANA.
Pros:
- Pre-collected data can be brought into SAP HANA
- Any data collection and remodelling can be done in Hadoop
- ETL is used for periodic data load from Hadoop
- Easy to configure and setup and does not require any separate configuration in Hadoop
Cons
- Cannot consume real time data
- Useful only for data of small sizes.
- Loading large, structured Hadoop datasets will result in memory loads and also make SAP HANA expensive
Scenario 2: Using Smart Data Access / Smart Data Integration
SAP Smart Data Access (SDA) allows SAP HANA to connect and virtually access data remotely without any need for data to move into SAP HANA. In our case, the tables are consumed as virtual tables and the SQL query is run directly in Hadoop.
SAP HANA Smart Data Integration (SDI) is the integrated component of SAP HANA which allows for seamless integration with external systems (here Hadoop) without the need for any separate, heterogeneous, non-native tier between the source and SAP HANA. Smart Data Integration is supported from SAP HANA SPS09 and further enhanced in SAP HANA SPS10 making it one of the ideal solutions for bringing real-time data from external systems. In our case, SDI facilitates real-time replication of data from Hadoop to SAP HANA. The data can be either pulled on demand when any query executes. When data in Hadoop changes or gets updated, it gets automatically pushed into SAP HANA.

As of the latest version, SAP HANA supports Hive connector (using JDBC), HDFS (using File adapter), SQL on top of Spark (using SAP HANA Spark controller) and direct Hadoop (using ODBC).
Please refer SAP Note 1868209, 1868702 and 2257657 to know more about SDA Integration with Hadoop.
Pros:
- Pre-collected data can be brought into SAP HANA
- Data collection and modelling can be done in Hadoop
- Supports real-time data using SDA; Batch loads are done using SDI
Cons
- Need to install separate component on Hadoop layer for SDI
- Complex than using ETL
Scenario 3: Using SAP HANA VORA as a processing tier with Hadoop
SAP VORA is an in-memory query engine which plugs into apache Hadoop framework to provide interactive analysis. VORA uses SPARK SQL library and compute engine from SAP. SAP HANA VORA can work as standalone component on Hadoop nodes.
SAP HANA VORA provides advanced processing capabilities that were not possible before. It can read data from SAP HANA to Spark and can write the data back on to SAP HANA. Since it runs on spark, it also provides many advanced functionalities that are offerhttps://visualbi.com/wp-admin/post.php?post=17507&action=edited by spark for data processing.
SAP VORA also brings the SQL-like capabilities of SAP HANA on top of Hadoop with help of views and in-memory tables.
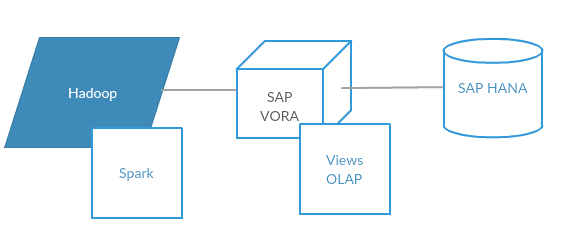
Pros:
- Can directly read data from SAP HANA and write back the processed data (to SAP HANA)
- It provides in-memory capability to build views
- Advanced data processing can be done with help of spark
Cons:
- Needs additional setup
- Requires a bit of programming knowledge for effective implementation & operations
Conclusion
As seen above, each option has its own benefits and drawbacks, and is suited for specific types of use cases.
New NetWeaver Information at SAP.com
Very Helpfull