
Dark Side of Groovy Scripting: Behind the Scenes of Cloud Platform Integration Runtime
Disclaimer
Material in this blog is provided for information and technical features demonstration purposes only. Described techniques and published code snippets, even in case they make sense from technical perspective, shall be a subject for assessment and evaluation from legal perspective to avoid violation of software license agreements, should the one attempt making use of them and embed them or their variations into the application deployed on SAP Cloud Platform or any other development that utilizes services provided by SAP Cloud Platform. Ultimately, we are good citizens and our aim is not to break the platform or rules of its usage, but to explore it and build smart applications on top of it.
When using approaches such as those described in the blog, please be cautious regarding how techniques are utilized and applied – they can be of great help, but equally to this, inaccurate usage of some of these techniques may cause severe stability and performance issues at runtime. Hence, before using this kind of techniques in real life applications and especially in production environments, ensure their usage is well considered, designed, implemented and well tested.
Intro
In this blog, I would like to share few tips that might be helpful to those of us who would like to explore runtime context of Java-based applications in SAP Cloud Platform or its specific services, based on examining of some aspects of SAP Cloud Platform Integration (CPI) runtime – such as, looking into properties and startup parameterization of CPI server nodes from perspective of Java Virtual Machine (JVM), identifying which methods are available for a given class in question and how they are implemented, what content of respective class files (as well as other arbitrary files accessible by the server node) is, how directory layout looks like, and so on. The blog undercovers and lightly touches some techniques that can be used for deeper and more thorough analysis of certain areas of runtime and underlying components, if required – in that sense, aim of the blog is not to provide complete solution, but rather direction of travel and concepts that can be applied in practice.
Techniques described in the blog, were introduced in Java / Groovy Development Kits (JDK/GDK) and JVM quite some time ago, and many of them are effectively used in variety of applications and products. Reason and motivation for me to draw attention to them here and now is driven by major shift to cloud based provisioning and deployment of services and applications, which makes it impossible or very complicated to use many runtime analysis approaches and tools that are common in on-premises solutions, as well as “black box” nature of cloud services’ insides in comparison to on-premises systems (where investigation process could lead us to the ground level). High level of abstraction and inability to naturally and comfortably deep dive into platform internals from customer side perspective are common in the cloud world, but together with this they bring certain restrictions when it comes to platform exploration journey. Let’s see how we can bring cloud to ground and explore what gems are hidden under the hood – and to evidence that this kind of helpful information can be practically obtained with the help of just few lines of code.
Code snippets presented in this blog are developed in Groovy language and were executed in one of CPI tenants, in context of a sample CPI flow, in a Groovy script step. I have chosen Groovy language for demos because of its compactness and some handy programming shortcuts it provides to the developer, although clear majority of code snippets can be re-implemented in Java and embedded into pure Java application.
In code snippets’ listings, imports section of the script is omitted for readibility purposes and only script’s method implementation containing the actual discussed logic, is provided. Inputs are mostly provided as String objects containing required parameters, and outputs are mostly provided in a form of message’s attachments and are pure plain text / plain text of key-value pairs to keep it simple and don’t distract attention to interaction / representation logic, but keep us focused on core discussed features. When being adapted, input / output format can be adjusted depending on specific needs – for example, converted to JSON, parameterized with externally provided arguments (such as parameters retrieved from processed request message or UI / frontend), embedded into the processed message body, etc. – for all this, Groovy language and CPI platform provide handy APIs.
The only essential bit here is development of such an application that can be compiled into Java bytecode and executed in JVM context. Note that CPI here is used only for demonstration purposes and aims better illustration of the discussed concept and its usage – described approaches can be implemented and embedded in variety of other Java-based applications – Java application deployed on SAP Cloud Platform and flow deployed on CPI are just couple of examples.
Since the whole idea of the discussed exercise is to look under the hood of CPI runtime, I will not be focused on the flow itself, but on ways how details about flow runtime can be obtained – and to achieve this, few techniques will be utilized, namely:
- JVM system properties,
- Java Management Extensions (JMX),
- Java Reflection API,
- General I/O and encoding APIs provided in GDK.
JVM runtime: exploring JVM properties and startup parameterization
Foundation of every executed Java / Groovy application is JVM in which context and runtime that application is executed. Hence, it is no surprise the one may want to investigate configuration of the JVM to figure out specific aspects of configuration that might impact or introduce risks / restrictions to the developed application. JVM system properties and JVM startup arguments (parameters) are two primary and essential areas to be looked at when addressing this question.
JVM provides access to runtime properties via System class, the approach is illustrated in the code below.
Code snippet:
def Message processData(Message message) { StringBuilder builder = new StringBuilder(); System.properties.each { key, value -> builder << "${key}=${value} " }; def messageLog = messageLogFactory.getMessageLog(message); messageLog.addAttachmentAsString("JVM system properties", builder.toString(), "text/plain"); return message; }Output:

For example, glancing through the output list of properties and their values, we can get a hint that the used CPI tenant runs on SAP JVM 7 (java.home=/usr/lib/jvm/sapjvm_7/sapjvm_7/jre) and is compliant to Java version 7 (java.version=1.7.0_141) – hence, when developing for this tenant, we are now aware our flows shall not include custom development that involves features which have been introduced in later Java versions such as 8 or 9, and shall not make use of 3rd party libraries that were only compiled for Java 8 and higher, and were not downported to Java 7.
Another note: listed properties contain some helpful information about used underlying application server Eclipse Virgo that runs in Apache Tomcat container, including references to configuration files – this all might become useful for further in-depth investigation.
Our next aim is to explore startup arguments of JVM – this information is essential when looking into memory configuration, garbage collector (GC) configuration, some aspects of threads configuration, some JMX parameterization, exposed JVM listeners’ ports configuration and so on.
To achieve this, I utilize JMX and make use of corresponding MXBeans. The example below illustrates usage of Runtime MXBean to retrieve all JVM startup arguments.
Code snippet:
def Message processData(Message message) { StringBuilder builder = new StringBuilder(); RuntimeMXBean runtimeMXBean = ManagementFactory.runtimeMXBean; runtimeMXBean.inputArguments.each { builder << "${it} " }; def messageLog = messageLogFactory.getMessageLog(message); messageLog.addAttachmentAsString("JVM startup arguments", builder.toString(), "text/plain"); return message; }Output:

From the above output, it can be seen that JVM has been started with relatively smaller maximum heap size (in comparison to commonly used average sized server nodes configuration of on-premises PI/PO systems) – only 1,2 Gb (-Xmx1224m) in contrast to default 4 Gb of maximum heap size per standard PI/PO server node. This is an outcome of compute unit sizing that was applied to this specific CPI tenant, and that can be checked by looking at argument ‘com.sap.it.node.vmsize’ (here, -Dcom.sap.it.node.vmsize=LITE), which corresponds to the smallest size of the allocated compute unit in SAP Cloud Platform out of four available standard sizes. This is a good note to keep in mind when considering implementation of flows with high parallelism or significantly large messages processing – extreme cases can cause shortage of allocated memory and bring unwanted Out of Memory exception in the JVM. Although it shall be noted here that production tenants and VMs will normally be sized using larger compute unit sizes, so observation above is mostly valid for development and other kinds of non-production tenants.
It can be noted that JVM is instructed to use Concurrent Mark Sweep (CMS) GC algorithm (-XX:+UseConcMarkSweepGC), with no specific GC algorithm tuning and fairly standard parameterization for GC logging – somewhat similar to setup commonly faced in current default PI/PO installations.
Another point of interest is, this particular tenant’s JVMs are not instrumented with statically loaded Java agents (otherwise, we would evidence existence of argument ‘-javaagent’) – in contrast to on-premises SAP NetWeaver Java Application Server based systems (such as PI/PO or EP), where common recommendation is to employ centralized monitoring infrastructure (such as Wily Introscope). In on-premises world, this implies necessity of installation of the agent (such as Wily agent) and instrumentation of server nodes with it, so that the agent is loaded during JVM startup and submits monitoring information to the central component (such as Wily Enterprise Manager) on regular intervals. Luckily, there are other alternatives (such as JMX and its feature-rich set of MXBeans) that can be used to retrieve a lot of monitoring information from running JVMs without need of agent static loading.
It shall be noted that JVM provides large variety of other MXBeans that can be obtained from ManagementFactory in a similar way and utilized to access many useful JVM monitoring and management functions – here are few of them to mention:
- Threads information (monitoring of resources consumption by thread, thread dumping, etc.) – ThreadMXBean,
- Memory information (monitoring of heap and non-heap memory areas usage, etc.) – MemoryMXBean,
- GC information (monitoring of number of GC runs, etc.) – GarbageCollectorMXBean,
- Class loading information (monitoring of number of loaded and unloaded classes, etc.) – ClassLoadingMXBean.
Comprehensive information on JMX API in general and MXBeans in particular can be found in JDK documentation. Note that some of these features are already accessible from SAP Cloud Platform’s cockpit, in JMX Console of the monitored Java application, and make use of the same concept of MXBeans usage – here in the blog the aim is demonstration of programmatic invocation of required MXBeans from arbitrary custom code.
Class members: looking into class definition and exploring available class methods and properties
Another frequently faced question is to find class members – namely, which methods (and with which signatures) and properties the class in question provides. This is essential when figuring out how the class can be used in the development – for example, which properties can be accessed, which methods can be invoked with which arguments and what return type can be expected. Commonly, this sort of information can be found in corresponding documentation – such as JavaDoc in Java world. But what if JavaDoc is not available and product documentation doesn’t provide this level of details? With the help of Java Reflection API, we can retrieve this information from runtime.
Before moving onwards, I strongly recommend reading the blog written by Morten Wittrock, where he has already addressed this question and provided extensive description on how to list methods available for the class ‘com.sap.gateway.ip.core.customdev.util.Message’ – excellent demonstration of the mentioned concept / Reflection API usage.
Let’s base an example on the same familiar class Message – this step is sort of repetition of what Morten has already described, but it is logically required and is a prerequisite for us moving on with further techniques described in the blog, so is placed here in sake of completeness. The below code snippet retrieves and lists all methods provided by that class.
Code snippet:
def Message processData(Message message) { String className = "com.sap.gateway.ip.core.customdev.util.Message"; StringBuilder builder = new StringBuilder(); Class clazz = Class.forName(className); clazz.methods.each { builder << "${it} " }; def messageLog = messageLogFactory.getMessageLog(message); messageLog.addAttachmentAsString("Class methods", builder.toString(), "text/plain"); return message; }Output:
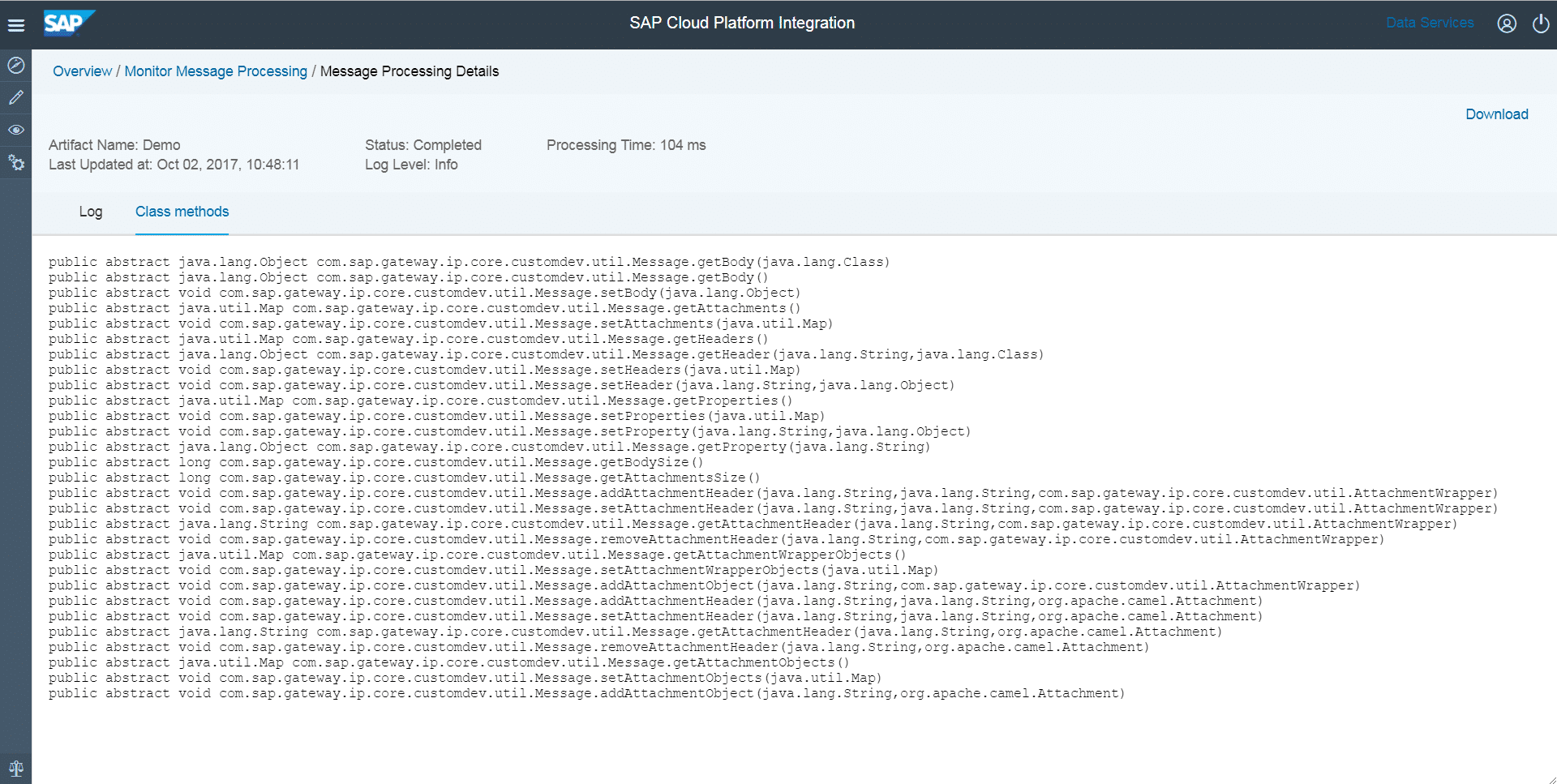
In a similar way, other members of a class (for example, properties) can be obtained.
Class file: looking into class implementation
Using the above approach, we can get to know class members of the class in question – in other words, we are equipped with information about declaration (or definition) of the class to answer questions like “Which class methods are available?”, “How the specific class method can be called?” and “Which class properties can be accessed?”. Now the time is to make one step forward and to look into implementation of the class to answer questions like “How the specific class method is implemented?” and “What logic is executed when the specific method is called?”.
To achieve this, we can make use of JVM class loaders and identify, which class file (the file containing bytecode of the compiled class) was used by JVM to load the class. Possessing this information, we can then retrieve content of that specific class file – for this, we will commonly end up obtaining corresponding JAR file that bundles multiple class files, including the one in question, and decompiling the file locally.
First things first – given the known fully qualified name of the class, Java Reflection API and JVM class loaders can be used to find location of the class file for it – to be more precise, the JAR file that contains corresponding class file. Following steps will extend the earlier example with the class Message.
Code snippet:
def Message processData(Message message) { String className = "com.sap.gateway.ip.core.customdev.util.Message"; StringBuilder builder = new StringBuilder(); builder << "Fully qualified class name: ${className} "; Class clazz = Class.forName(className); URI classFilePath = clazz.protectionDomain.codeSource.location.toURI(); builder << "JAR file containing class file: ${classFilePath} "; def messageLog = messageLogFactory.getMessageLog(message); messageLog.addAttachmentAsString("JAR file location", builder.toString(), "text/plain"); return message; }Output:

After JAR file location is known, we can access its content. Since file content is binary, there are few primary options to choose from:
- The most straightforward option is to retrieve byte array of file’s content and send it somewhere exactly as raw byte array in such a way that the new file with same raw byte array content is created (examples of destinations can be mail message with binary file attachment, file created at remote SFTP server, binary file download to the client machine, etc.),
- Alternative option is to encode obtained binary content of the file into Base64 string and transmit encoded version of file content. This option is appropriate for use cases, when transmission of raw byte array is not possible or is not convenient.
In the demo, I will use the latter option and follow steps below:
- Firstly, file path to the JAR file containing the class file for the class Message is identified (using JVM class loaders),
- Then binary content of the identified JAR file is retrieved (using GDK File I/O API),
- Finally, retrieved binary content is encoded in Base64. In the demo, composed Base64 text string is only displayed in output, so that it can be manipulated further – for example, it can be copy-pasted and decoded locally back to binary form, and saved to a newly created JAR file, which would be replica of the original and exact copy of it content-wise.
Code snippet:
def Message processData(Message message) { String className = "com.sap.gateway.ip.core.customdev.util.Message"; StringBuilder builder = new StringBuilder(); Class clazz = Class.forName(className); URI classFilePath = clazz.protectionDomain.codeSource.location.toURI(); File classFile = new File(classFilePath); byte[] classFileContent = classFile.bytes; builder << classFileContent.encodeBase64().toString(); def messageLog = messageLogFactory.getMessageLog(message); messageLog.addAttachmentAsString("JAR file content: Base64 encoding", builder.toString(), "text/plain"); return message; }Output:

Side-note: there are online and standalone tools for Base64 encoding/decoding, as well as such functionality can be achieved using standard JDK/GDK File I/O API. For example, in Groovy, the simplest realization will look like:
class Base64Decoder { static main(args) { if (args.length < 2) { System.err.println "One or several mandatory arguments are missing"; System.exit(1); } File fileBase64 = new File(args[0]); File fileBinary = new File(args[1]); fileBinary.bytes = fileBase64.text.decodeBase64(); } }where the first argument is path to the file containing Base64 encoded data (string) and the second argument is path to the file to be generated with binary content (for example, JAR file).
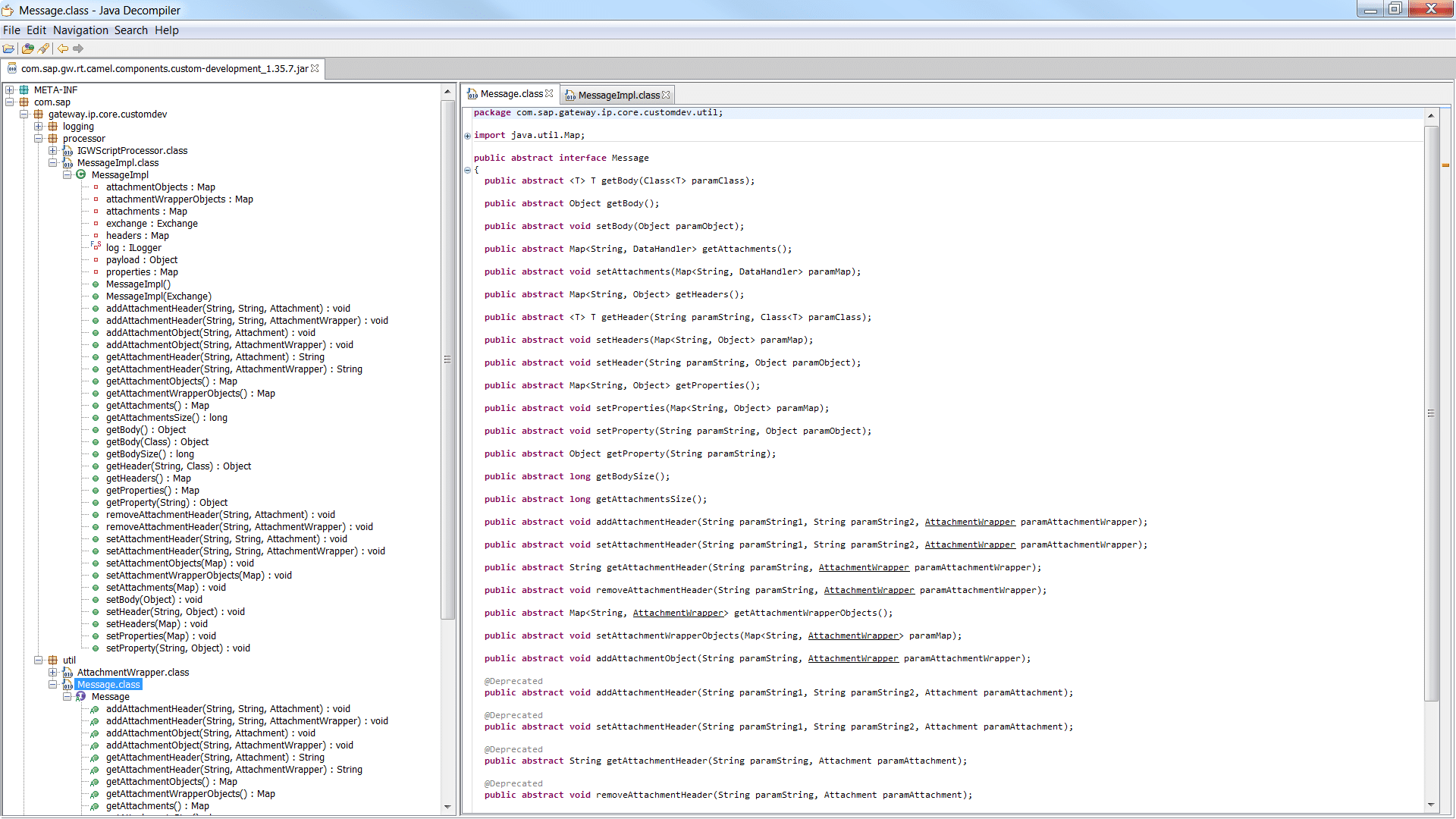
Finally, we can decompile the obtained JAR file and explore implementation of classes or definition of interfaces contained in it. I will not go here in details of Java class files decompilation – there were already several blogs posted on SAP Community, as well as non-SAP related resources dedicated to this topic. Personally, I often use JD-GUI for Java decompilation – and here is a sample result that is achieved for the examined class (both interface definition and class implementation):

Directories and files: browsing directories and retrieving content of arbitrary files
In the example above, we already accessed the given determined file. To make step forward and extend that example, we can also examine specific directories (or directories with their sub-directories recursively), list directories’ content and search for files, retrieve properties and content of arbitrary files of the application server that are accessible for the server node. This might be helpful when the one needs to get familiar with directories layout or retrieve content of log or trace files for further troubleshooting / detailed investigation of the problem.
Let’s get back to the demo. From previous steps, we got to know that class file containing implementation of the class Message, is located in the JAR file which can be found in the folder ‘/usr/sap/ljs/plugins/’. Now let’s browse content of that directory and see what other JAR files are located there.
Code snippet:
def Message processData(Message message) { String dirPluginsPath = "/usr/sap/ljs/plugins/"; StringBuilder builder = new StringBuilder(); File dirPlugins = new File(dirPluginsPath); dirPlugins.eachFileMatch(~/.*.jar/) { builder << "${it.name} " }; def messageLog = messageLogFactory.getMessageLog(message); messageLog.addAttachmentAsString("Directory browser: JAR files", builder.toString(), "text/plain"); return message; }Output:

Lots of things to explore! Please note that the directory contains both SAP and 3rd party (Apache Camel, Eclipse Virgo, etc.) libraries / binaries and their dependencies, that all together contain major part of compilation of components required to run deployed applications.
Another use case for this technique is to examine structure of folders of the application server – for example, starting from the application server’s root directory and recursively going down to all sub-directories.
Code snippet:
def Message processData(Message message) { String dirInstanceRootPath = "/usr/sap/ljs/"; StringBuilder builder = new StringBuilder(); File dirInstanceRoot = new File(dirInstanceRootPath); dirInstanceRoot.eachDirRecurse { builder << "${it.absolutePath} " }; def messageLog = messageLogFactory.getMessageLog(message); messageLog.addAttachmentAsString("Directory browser: Directory tree", builder.toString(), "text/plain"); return message; }Output:

For sure, this approach is very flexible depending on specific requirements – for example, commonly faced use case will involve application of certain search patterns / filtering of folders and files by name, extension or other properties.
Access to file content by file location / path – being it binary data such as class files / executable files (hence, reading file content into raw byte array) or text data such as configuration files / log files (hence, reading file content into raw byte array, or alternatively into strings / other characters handling types) – can be realized in a similar way as it was demonstrated in the section above when accessing content of the JAR file, using File I/O API.
Outro
The above examples demonstrate small fraction of entire capabilities that are exposed by SAP Cloud Platform and that can be utilized for large variety of use cases and embedded in different Java / Groovy applications, and shall hopefully be a good illustration of flexibility and power that is available to developers via means of standard JDK/GDK and JVM APIs in application to cloud services and their runtimes. As it can be seen, there is a lot that can be explored and analyzed – and developers are provided capabilities that enable this discovery process.
Acknowledgements
The key idea of this blog was inspired by and originates from discussions with Eng Swee Yeoh and his thorough thoughts and accurate remarks. His comments, comprehensive findings and expert knowledge that he shared when described ideas were on a basic level and far from being concrete, significantly helped me in shaping and improving content of the blog.
Special thanks go to Yuri Popov and Vyacheslav Kuzyakin for their help, fruitful discussion and invaluable feedback on some pitfalls and corner cases – both technical and non-technical.
New NetWeaver Information at SAP.com
Very Helpfull