
Many SAP Data Services (DS) applications use SAP ECC data as a source. It now happens that DS supports multiple mechanisms to extract data from SAP ECC. Which one to choose? There often is a preferred method, depending on the functionality required and on the capabilities offered within the actual context of the source system. In this blog, I discuss all different options.
Start with configuring a data store for the SAP source system:

Figure 1: SAP Data store definition
Mandatory settings are User Name and Password, the name (or IP address) of the SAP Application server, the Client and System (instance) number.
1/. “Regular” data flow
When extracting from a single table, do that in a standard data flow. Import the table definition from the Metadata Repository in the Data store Explorer and use it as source in a data flow.
An extraction from the KNA1 customer master data table looks like this:

Figure 2: Data flow – extract from KNA1
Note the little red triangle in the source table icon. It’s an indication of a direct extract from the SAP data layer.
This is the simplest method. No special measures are necessary at the level of the source system. The extraction will run as a SAP dialog job. Note that there is a time-out setting (system-configurable, typically 10, 30, 60 minutes) for dialog jobs. The DS job will fail when data extraction takes longer.
The where conditions are pushed down to the underlying database. This is beneficial for the job performance. Also, make sure to extract only the columns that are really required. The extraction process duration is linearly related to the data volume, which equals number of records * average records size. The less data is transferred, the faster the DS job runs.

Figure 3: Query transform – extract from KNA1, excluding obsolete records

Figure 4: Generated SQL code – the where-clause is pushed down
This approach is especially beneficial when implementing incremental loads. When the source table contains a column with a last-modification timestamp, you can easily implement source-based changed-data capture (CDC). Keep track of the timestamps you used in the previous incremental extraction (use a control table for that), initialize global variables with those values and use them in the where-clause of your Query transform.

Figure 5: Query transform – extract recently created or modified records from MARA

Figure 6: Generated SQL code – source-based CDC
2/. ABAP data flow
Although where-conditions are pushed down to the underlying database from a normal data flow, the joins are not (sort and group-by operations aren’t either!), often leading to abominable performance, especially when dealing with larger data volumes.
When you want to extract material master data from MARA and supplement each record with the English material description from MAKT, you can build a data flow like this:

Figure 7: Data flow – extract from MARA and MAKT
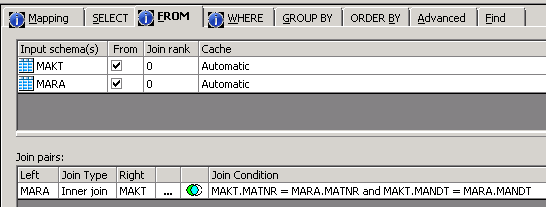
Figure 8: Query transform – join MARA and MAKT on MANDT and MATNR columns


Figure 9: Generated SQL code – no join
DS generates two SQL statements. It first extracts all current records from MARA. And then for each individual record it retrieves the corresponding English description (MATNR = AIVariable_1 and MANDT = AIVariable_2). That approach leads to as many round-trips to the underlying database as there are records in the MARA table! It is only a valid one when dealing with smaller sets of data.
You may improve performance by changing the properties of the source tables.
The default settings are:

Figure 10: Default source table properties
Making MARA the driving table (by giving it a higher Join rank than MAKT) and caching MAKT in memory leads to a completely different generation of SQL code, without singular round-trips to the database. The MARA table streams through the data flow, the MAKT table is cached, and the join is resolved in DS memory.


Figure 11: Modified source table properties


Figure 12: Generated SQL code – cache MAKT
The feasibility of this approach is impacted by 2 parameters:
- The amount of memory available for caching
- The time it takes to cache the MAKT table
This works perfectly for smaller tables. But it’s not a well performing solution either when MAKT and MARA are too large
The recommended solution for extracting from a join of SAP tables is through the use of an ABAP data flow.

Figure 13: ABAP Data flow – extract from MARA and MAKT
DS generates ABAP code corresponding to the properties of the source tables and the logic of the dataflow. The table with the highest Join Rank becomes the driving table. Also in this case, the duration of the extraction process is linearly related to the data volume: the less data is transferred, the faster the DS job runs.

Figure 14: Generated ABAP code
The ABAP code is pushed to the SAP system and executed there. The program results only are sent back to DS for further processing. This approach only works when the SAP system is open for development! Also, make sure that:
- The ABAP execution option is set to Generate and Execute.
- The Execute in Background (batch) property is set to Yes to avoid the time-out in SAP dialog jobs.
- The Data transfer method is set to RFC. The RFC destination must be defined in the SAP system. The other Data transfer methods are there for upward-compatibility reasons only and must not be used anymore. They all lead to inferior performance.

Figure 15: SAP Data store definition
To execute the same DS job in non-development tiers of your landscape, transport the ABAP program from DEV to TST, PRD… first. Set the ABAP execution option to Execute Preloaded and run the DS job. It will not generate the ABAP code again, but execute the transported code.
ABAP data flows are also a convenient solution for implementing incremental loads for ECC tables that do not contain a last-modification timestamp column. Inserts and modifications in KNA1 are registered in the CDHDR and CDPOS tables. Use an ABAP data flow to join KNA1 to those tables. Make sure CDHDR gets the highest Join Rank, KNA1 the lowest, in order to get the most efficient code generated. And include the where conditions to:
- Filter out current customers
- Get the recently modified records only
- From the correct entries in the log tables

Figure 16: ABAP Data flow – extract from KNA1

Figure 17: Query transform – join KNA1 with CDHDR and CDPOS

Figure 18: Query transform – extract recently created or modified records from KNA1
3/. SAP Extractor
SAP Extractors are tailored for BW Business Content. They contain all the logic for common business transformations, possible aggregations, and also how to identify changes already, so they are very suitable for implementing incremental loads.
The DS Extractor feature is built on top of the Operational Data Provisioning (ODP) API. DS supports all types of ODP sources supported by the ODP API, including CDC functionality.
In a regular data flow, DS uses RFC to call the ODP data replication API. The where-conditions are not pushed down to the extractor. That means all data are pulled from the extractor and filtering is done afterwards in DS. Import the ODP object definition from the Metadata Repository in the Data store Explorer.

Figure 19: Import extractor 0CUSTOMER_ATTR
Make sure to set the Extraction mode to Query. Then use it as source in a data flow. An extraction from the 0CUSTOMER_ATTR ODP object looks like this:

Figure 20: Data flow – extract from 0CUSTOMER_ATTR
If you want to extract a minor subset of the data only, use the ODP object as source in an ABAP data flow.

Figure 21: ABAP data flow – extract from 0CUSTOMER_ATTR
Add the where-clause to the Query transform.

Figure 22: Query transform – extract current American customers from 0CUSTOMER_ATTR
DS generates the ABAP that calls the ODP data replication API. The generated code contains the logic for filtering out unnecessary records.

Figure 23: Generated ABAP code
Implementing CDC is really a piece of cake for those extractors that are “delta-enabled”. Make sure to set the Extraction mode to Changed-data capture (CDC). When import the ODP object.

Figure 24: Import extractor 0PROJECT_ATTR
Then use it as source in a data flow. No need to add any time-based condition in the where-clause. The extractor logic will guarantee that only new and modified records are passed to DS. Just make sure that the Initial load property of the ODP object is set to No. Only set it to Yes when you want the target table to be re-initialized.

Figure 25: ODP object properties
Include a Map_CDC_Operation transform to automatically synchronize the target table with the source object. The transform will translate the Row Operation value into the corresponding DS row type:
- I > Insert
- B & U: before and after-image of an Update
- D > Delete

Figure 26: Data flow – delta extract from 0PROJECT_ATTR
4/. ECC function
DS can call RFC-enabled ECC functions returning tables as data flow sources, as well. If a standard ECC function is not RFC-enabled, you need an RFC-enabled wrapper function that passes the parameters to the standard function, calls it and forwards the results to DS.
You can only import a function’s metadata by name. Call it from a query transform by selecting New Function Call… from the pop-up menu in its output schema. Select the function from the ECC data store. Define Input Parameter(s) and select Output Parameter. The function call is added to the output schema.




Figure 27: Query transform – call an ECC function
Then unnest the return results in a next Query transform before writing it into a target table.

Figure 28: Query transform – unnest the function output schema
5/. SAP LT (SLT) Replication Server
DS can use SLT Replication Server as a source. This is a very neat and elegant way to build CDC jobs in DS. Working with SLT objects is similar to the way DS works with SAP extractors.
Define the SLT data store like any other SAP data store. Just make sure you select the right ODP context in the definition.

Figure 29: SLT Data store definition
You can then import the tables you need to extract data from.

Figure 30: SLT table metadata
Use the ODP object as source in a data flow. The first time the data flow is executed it will do a full extract of the underlying table. All successive runs will automatically perform an incremental one and only forward the delta.

Figure 31: Data flow – delta extract from MARA through SLT
6/. IDOC
DS real-time jobs can read from IDOC messages and IDOC files. DS batch jobs can only read from IDOC files.
Import the IDOC metadata definition by name from the SAP data store. Use the IDOC as a file source in a data flow within a batch job.

Figure 32: Data flow – delta extract from IDOC File Source
Double-click on the IDOC icon to open its definition and specify the name of the IDOC file. You can use wildcards (? and *) or list multiple file names separated by commas if you want to process multiple files in a single data flow.

Figure 33: IDOC properties
Generate the IDOC file(s) from SAP and run your DS job.
New NetWeaver Information at SAP.com
Very Helpfull